Serverless Inference
- ホスティングプロバイダーに登録したりモデルをセルフホストしたりすることなく、AI アプリケーションやエージェントを開発する。
- W&B Weave Playground でサポート対象モデルを試す。
このガイドでは、次の情報を提供します。
前提条件
- W&B アカウント。こちらからサインアップしてください。
- W&B APIキー。User Settings で APIキーを作成してください。
- W&B プロジェクト。
- Python 経由で Inference サービスを使用する場合は、Python 経由で API を使用するための追加の前提条件を参照してください。
Python 経由で API を使用するための追加の前提条件
openai と weave ライブラリをインストールしてください:
LLM アプリケーションのトレースに Weave を使用する場合にのみ、
weave ライブラリが必要です。Weave の利用を開始する方法については、Weave クイックスタートを参照してください。Weave で Serverless Inference サービスを使用する方法を示す API の使用例については、API の使用例を参照してください。API 仕様
エンドポイント
利用可能な method
Chat completions
/chat/completions です。これは、サポートされるモデルにメッセージを送信して補完を受け取るための OpenAI 互換の Request 形式をサポートします。Weave で Serverless Inference サービスを使用する方法を示す使用例については、API の使用例を参照してください。
チャット補完を作成するには、次が必要です。
- Inference サービスのベース URL
https://api.inference.wandb.ai/v1 - W&B APIキー
<your-api-key> - W&B entity 名とプロジェクト名
<your-team>/<your-project> - 使用するモデルの ID。以下のいずれかです。
meta-llama/Llama-3.1-8B-Instructdeepseek-ai/DeepSeek-V3-0324meta-llama/Llama-3.3-70B-Instructdeepseek-ai/DeepSeek-R1-0528meta-llama/Llama-4-Scout-17B-16E-Instructmicrosoft/Phi-4-mini-instruct
- Bash
- Python
サポート対象モデルを一覧表示
- Bash
- Python
使用例
基本例: Weave で Llama 3.1 8B をトレースする
- OpenAI 互換クライアントを使用して chat completion リクエストを行う、
@weave.op()でデコレートされた関数run_chatを定義します。 - トレースは記録され、W&B の entity とプロジェクト
project="<your-team>/<your-project>に関連付けられます - この関数は Weave によって自動的にトレースされるため、その入力、出力、レイテンシー、メタデータ (モデル ID など) がログされます。
- 結果はターミナルに出力され、トレースは指定したプロジェクト配下の https://wandb.ai の Traces タブに表示されます。
https://wandb.ai/<your-team>/<your-project>/r/call/01977f8f-839d-7dda-b0c2-27292ef0e04g) をクリックして、Weave でトレースを確認できます。あるいは、次の手順でも確認できます。
- https://wandb.ai にアクセスします。
- Traces タブを選択して、Weave のトレースを表示します。
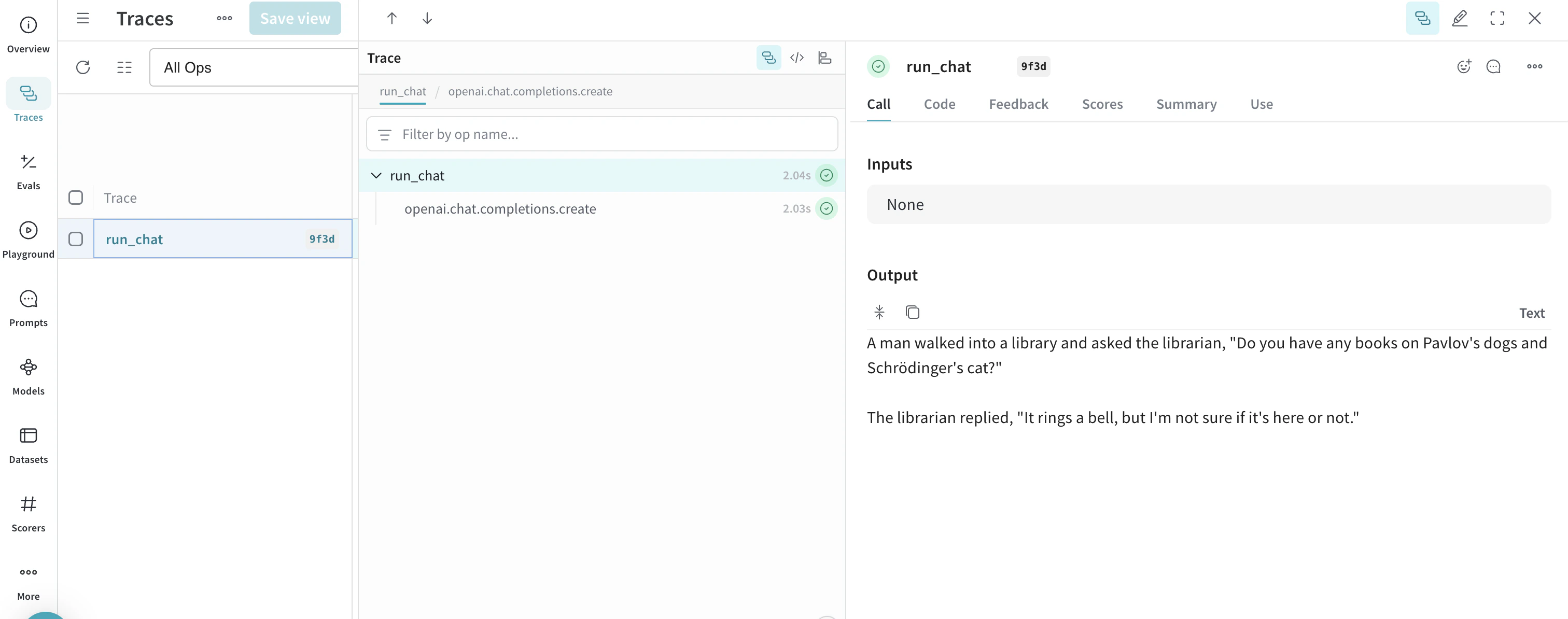
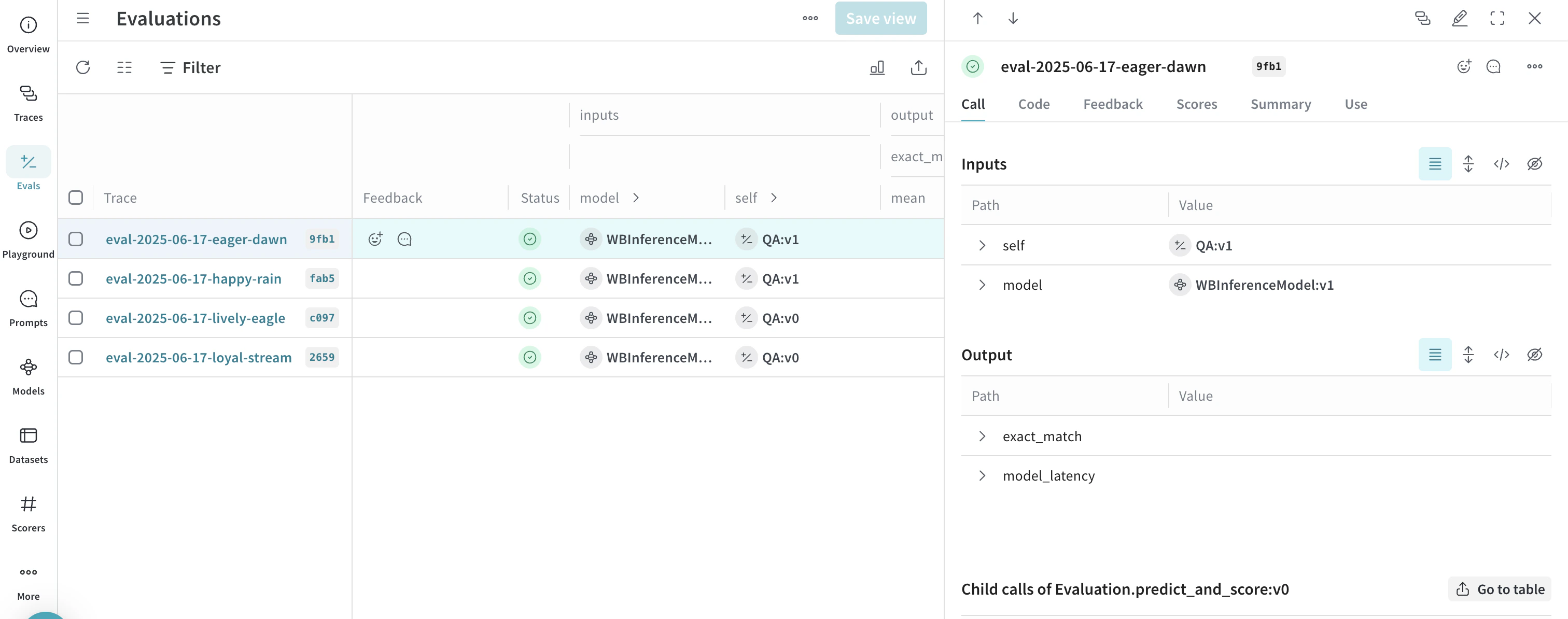
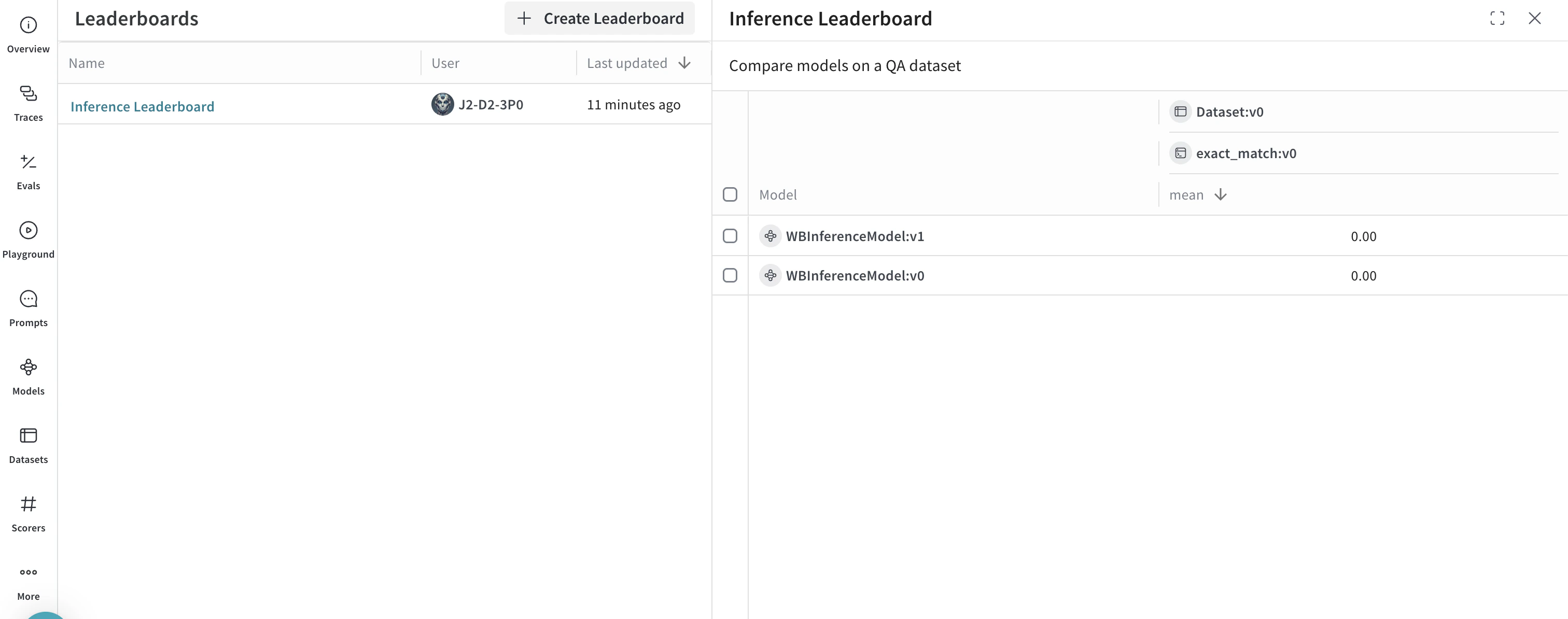
高度な例: Inference サービス で Weave の評価とリーダーボードを使用する
- Traces タブにアクセスして、トレースを表示します
- Evals タブにアクセスして、モデルの評価を表示します
- Leaders タブにアクセスして、生成されたリーダーボードを表示します
UI
Inference サービスにアクセスする
直接リンク
Inference タブから
- W&B アカウントにアクセスするには、https://wandb.ai/ を開きます。
- 左サイドバーから Inference を選択します。利用可能なモデルとその情報が表示されます。
Playground タブから
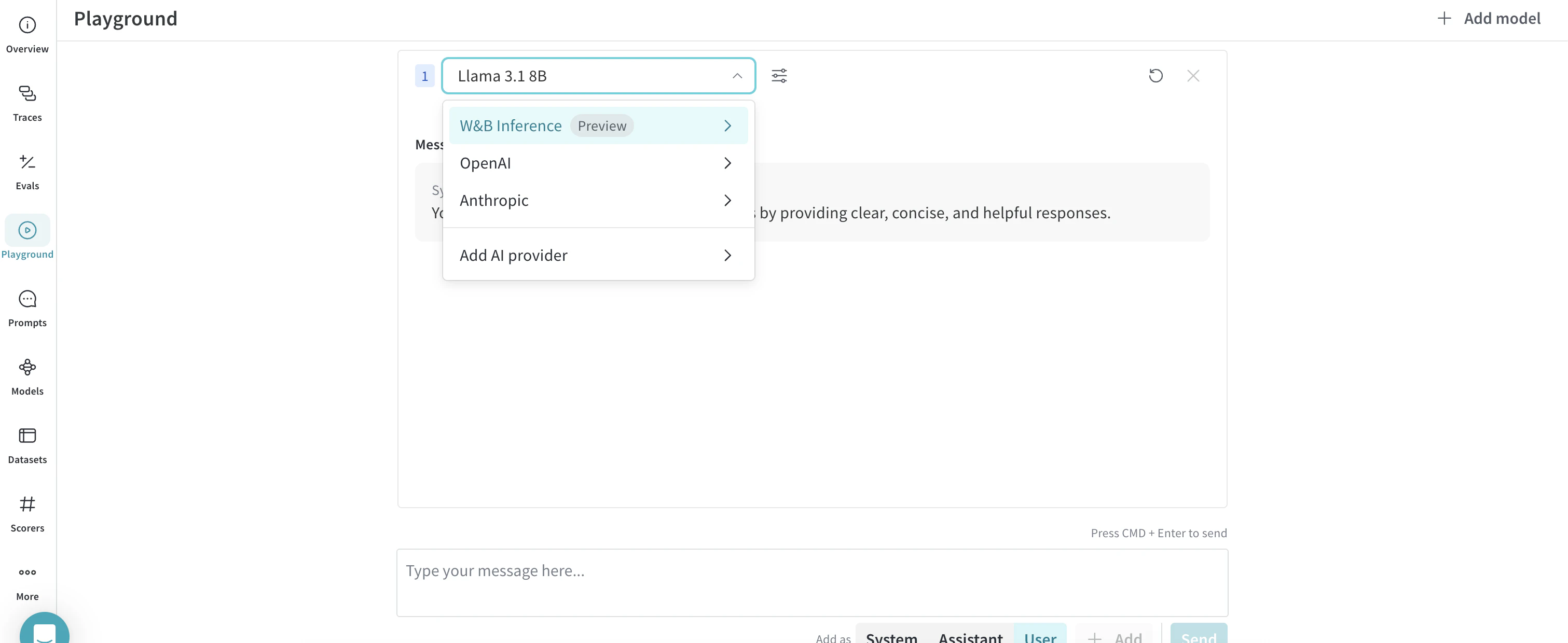
- 左サイドバーで Playground を選択します。Playground のチャット UI が表示されます。
- LLM のドロップダウンリストで Serverless Inference にマウスオーバーします。右側に、使用可能な Serverless Inference モデルのドロップダウンが表示されます。
- Serverless Inference モデルのドロップダウンから、次の操作を行えます。
- 使用可能な任意のモデルの名をクリックして、Playground で試すことができます。
- Playground で複数のモデルを比較する
Playground でモデルを試す
複数のモデルを比較する
Inference タブから Compare ビューにアクセスする
- 左サイドバーで Inference を選択します。利用可能なモデルとモデル情報が表示されたページが開きます。
- 比較するモデルを選択するには、モデルカード上の任意の場所 (モデル名を除く) をクリックします。選択されると、モデルカードの枠線が青色で強調表示されます。
- 比較したい各モデルについて、step 2 を繰り返します。
- 選択したいずれかのカードで、Compare N models in the Playground ボタンをクリックします (
Nは比較するモデル数です。たとえば、3 つのモデルを選択した場合、ボタンには Compare 3 models in the Playground と表示されます) 。比較ビューが開きます。
Playground タブから Compare ビュー にアクセスする
- 左サイドバーで Playground を選択します。Playground のチャット UI が表示されます。
- LLM のドロップダウンリストで Serverless Inference にマウスオーバーします。右側に、利用可能な Serverless Inference モデルを含むドロップダウンが表示されます。
- ドロップダウンから Compare を選択します。Inference タブが表示されます。
- 比較するモデルを選択するには、モデルカード上の任意の場所 (モデル名を除く) をクリックします。選択されると、モデルカードの枠線が青色で強調表示されます。
- 比較する各モデルに対して step 4 を繰り返します。
- 選択したいずれかのカードで、Compare N models in the Playground ボタンをクリックします (
Nは比較するモデル数です。たとえば、3 つのモデルを選択している場合、ボタンには Compare 3 models in the Playground と表示されます) 。comparison view が開きます。
請求と使用状況の情報を表示する
- W&B UI で、W&B の Billing ページにアクセスします。
- 画面右下に Inference の請求情報カードが表示されます。ここでは、次のことができます。
- Inference の請求情報カードにある View usage ボタンをクリックして、経時的な使用状況を確認します。
- 有料プランをご利用の場合は、今後の Inference の請求額を確認します。
利用に関する情報と制限
地理的制限
同時実行制限
- 不正利用を防ぎ、API の安定性を保つ
- すべてのユーザーが利用できるようにする
- インフラストラクチャーの負荷を効果的に管理する
429 Concurrency limit reached for requests レスポンスを返します。このエラーを解消するには、同時リクエスト数を減らしてください。